I attended the W-JAX 2019 conference beginning of November in Munich. It is a big conference for software developers and had somewhere between 1300 and 1500 participants. Here are some impressions and pictures.
This is the team preparing our booth: unpacking, setting up the background
front: Miriam and Thomas, back: Niklas and myself
Jason McGee, IBM Fellow, Vice President and CTO of IBM Cloud Platform gave a keynote on “The 20 Year Platform – bringing together Kubernetes, 12-Factor and Functions“.
Full house for Jason McGee
Emily Jiang, our MicroProfile hero from the IBM Hursley lab, did On Stage Hacking: “Building a 12-Factor Microservice“:
l2r: Thomas, Miriam, Niklas, Emily, Harald
Grace Jansen, Developer Advocate and also from the IBM Hursley lab, presented “Reacting to the Future of Application Architecture” :
The next IBM session at W-JAX was Niklas Heidloff and myself explaining “How to develop your first cloud-native app in Java“. I never had such an attentive audience asking so many clever questions … maybe giving out swag (T-Shirts with the cool IBM rebus logo) for asking good questions does help 🙂
And finally Jeremias Werner, Senior Software Developer at the IBM Böblingen lab, presented “A peek behind the scenes and how Knative is changing the serverless landscape” (unfortunately the link to his agenda topic doesn’t work: HTTP 404):
Between the talks we were quite busy at the booth:
Some people work at a new career path as movie star 🙂
Thomas is interviewed by the W-JAX team
And of course Blue Cloud Mirror, our Open Source game project, was an attraction at the booth:
The team on day 1:
l2r: Andrea, Niklas, Miguel, Harald, Miriam, Jason, Thomas
Thomas posted a cool video on Twitter:
Meet our @IBMDeveloper team at @jaxcon, swing by and say hi 👋 play our #BlueCloudMirror game and discover more about @IBMcloud ☁️
The latest release of Istio — 1.4.x — is changing the way Istio is installed. There are now two methods, the method using Helm will be deprecated in the future:
Istio Operator, this is in alpha state at the moment and seems to be similar to the way Red Hat Service Mesh is installed (see here)
Using istioctl
I have tried the istioctl method with a Kubernetes cluster on IBM Cloud (IKS) and want to document my findings.
Download Istio
Execute the following command:
$ curl -L https://istio.io/downloadIstio | sh -
This will download the latest Istio version from Github, currently 1.4.0. When the command has finished there are instructions on how to add istioctl to your path environment variable. To do this is important for the next steps.
Target your Kubernetes cluster
Execute the commands needed (if any) to be able to access your Kubernetes cluster. With IKS this is at least:
$ ibmcloud ks cluster config <cluster-name>
Verify Istio and Kubernetes
$ istioctl verify-install
This will try and access your Kubernetes cluster and check if Istio is installable on it. The command should result in: “Install Pre-Check passed! The cluster is ready for Istio installation.”
Installation Configuration Profiles
There are 5 built-in Istio installation profiles: default, demo, minimal, sds, remote. Check with:
$ istioctl profile list
“minimal” installs only Pilot, “default” is a small footprint installation, “demo” installs almost all features in addition to setting the logging and tracing ratio to 100% (= everything) which is definitely not desirable in a production environment, it would put too much load on your cluster simply for logging and tracing.
Here is a good overview of the different profiles. You can modify the profiles and enable or disable certain features. I will use the demo profile, this has all the options I want enabled.
Installing Istio
This requires a single command:
$ istioctl manifest apply --set profile=demo
Verify the installation
First, generate a manifest for the demo installation: $ istioctl manifest generate --set profile=demo > generated-manifest.yaml
Then verify that this was applied on your cluster correctly: $ istioctl verify-install -f generated-manifest.yaml
Result (last lines) should look like this:
Kiali is Istio’s dashboard and this is one of the coolest features in 1.4.x: To open the Kiali dashboard you no longer need to execute complicated port-forwarding commands, simply type
$ istioctl dashboard kiali
Then login with admin/admin:
The same command works for Prometheus (monitoring) and Jaeger (tracing), too:
Last week I wrote about running OpenShift 4 on your laptop. This is using CodeReady Containers (CRC) and deploys a full Red Hat OpenShift into a single VM on a workstation.
You can install OpenShift Service Mesh which is Red Hat’s version of Istio into CRC. This is done using Operators and in this blog I want to write about my experience.
Please note: an unmodified CRC installation reserves 8 GB of memory (RAM) for the virtual machine running OpenShift. This is not enough to run Istio/Service Mesh. I am in the fortunate situation that my notebook has 32 GB of RAM, so in the article about CRC I have set the memory limit of CRC to 16 GB with this command:
$ crc config set memory 16384
You need to do that before you start CRC for the first time.
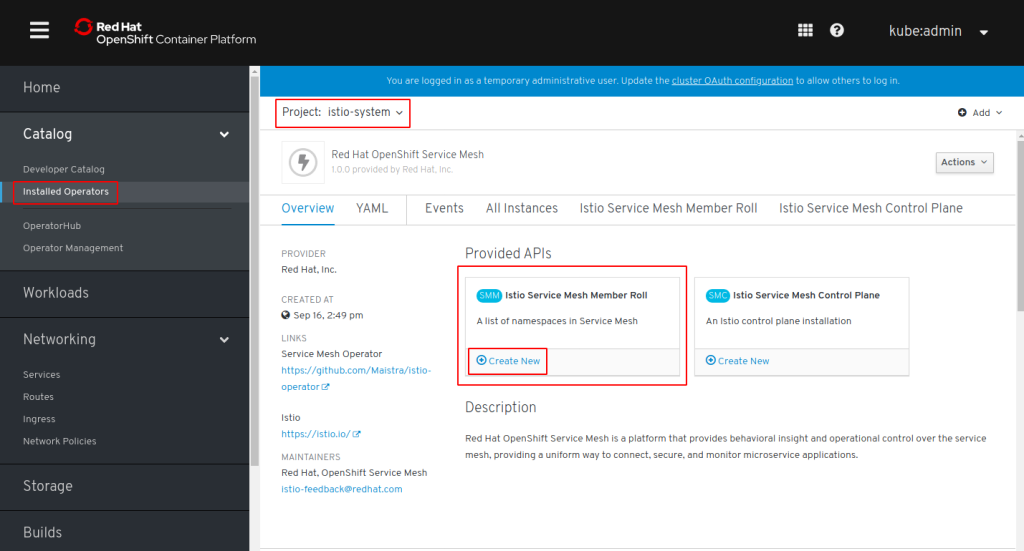
Install the Service Mesh Operators
Here are the official instructions I followed. OpenShift uses an Operator to install the Red Hat Service Mesh. There are also separate Operators for Elasticsearch, Jaeger, and Kiali. We need all 4 and install them in sequence.
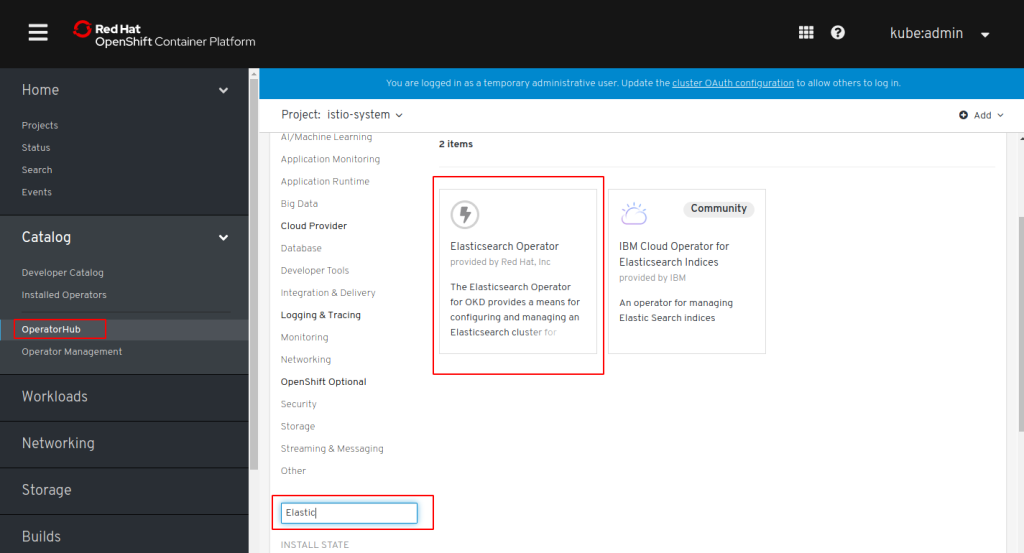
In the Web Console, go to Catalog, OperatorHub and search for Elasticsearch:
Click on the Elasticsearch (provided by Red Hat, Inc.) tile, click “Install”, accept all defaults for “Create Operator Subscription”, and click “Subscribe”.
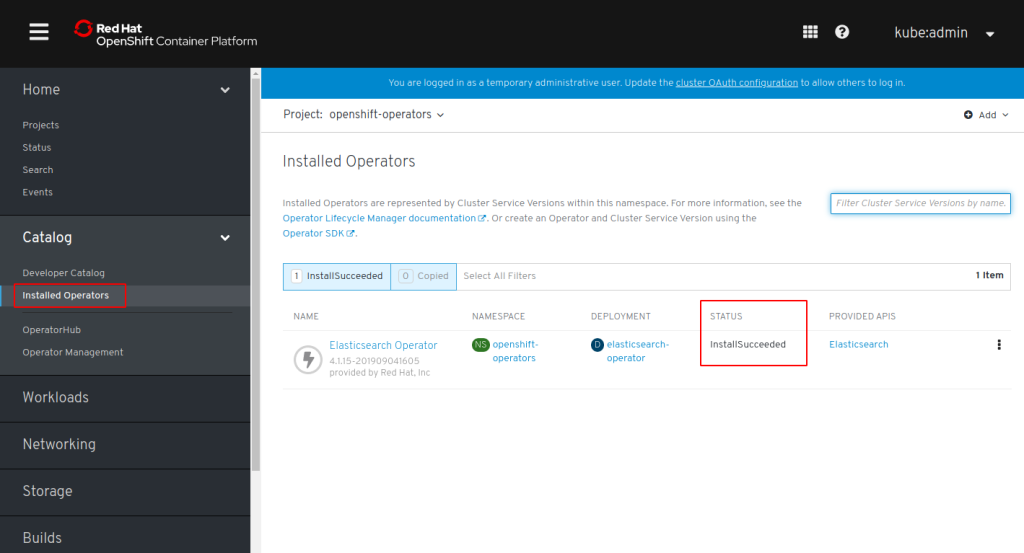
In the “Subscription Overview” wait for “UPGRADE STATUS” to be “Up to date”, then check section “Installed Operators” for “STATUS: InstallSucceeded”:
Repeat these steps for Jaeger, Kiali, and Service Mesh. There are Community and Red Hat provided Operators, make sure to use the Red Hat provided ones!
I don’t know if this is really necessary but I always wait for the Operator status to be InstallSucceeded before continuing with the next one.
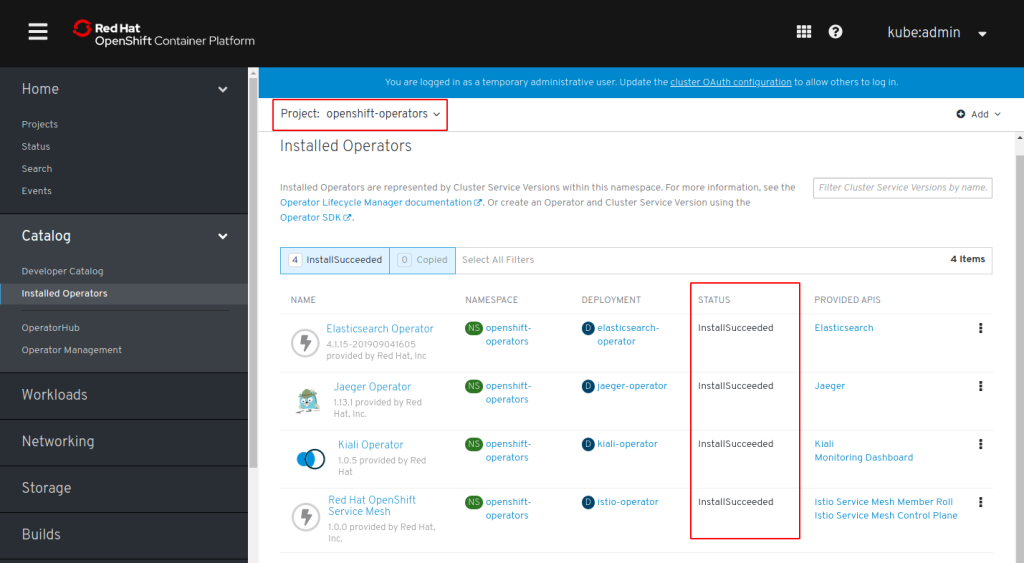
In the end there will be 4 Operators in Project “openshift-operators”:
Create the Service Mesh Control Plane
The Service Mesh Control Plane is the actual installation of all Istio components into OpenShift.
We begin with creating a project ‘istio-system’, either in the Web Console or via command line (‘oc new-project istio-system‘) You can actually name the project whatever you like, in fact you can have more than one service mesh in a single OpenShift instance. But to be consistent with Istio I like to stay with ‘istio-system’ as name.
In the Web Console in project: ‘istio-system’ click on “Installed Operators”. You should see all 4 Operators in status “Copied”. The Operators are installed in project ‘openshift-operators’ but we will create the Control Plane in ‘istio-system’. Click on “Red Hat OpenShift Service Mesh”. This Operator provides 2 APIs: ‘Member Role’ and ‘Control Plane’:
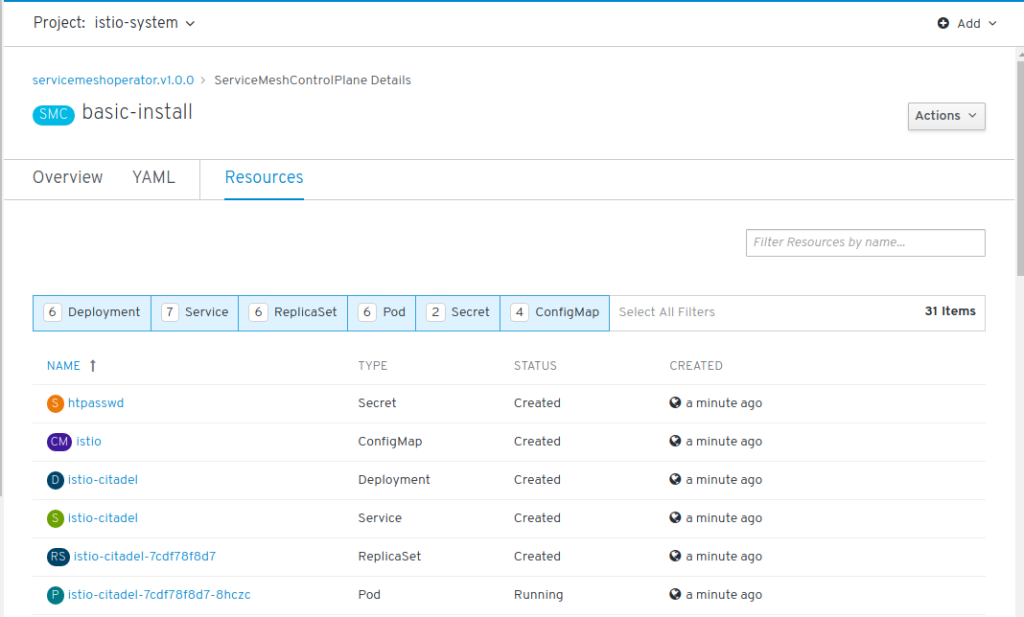
Click on “Create New” Control Plane. This opens an editor with a YAML file of kind “ServiceMeshControlPlane”. Look at it but accept it as is. It will create a Control Plane of name ‘basic-install’ with Kiali, Grafana, and Tracing (Jaeger) enabled, Jaeger will use an ‘all-in-one’ template (without Elasticsearch). Click “Create”.
You will now see “basic-install” in the list of Service Mesh Control Planes. Click on “basic-install” and “Resources”. This will display a list of objects that belong to the control plane and this list will grow in the next minutes as more objects are created:
A good way to check if the installation is complete is by looking into Networking – Routes. You should see 5 routes:
Click on the Routes for grafana, jaeger, prometheus, and kiali. Accept the security settings. I click on Kiali last because Kiali is using the other services and in that way all the security settings for those are in place already.
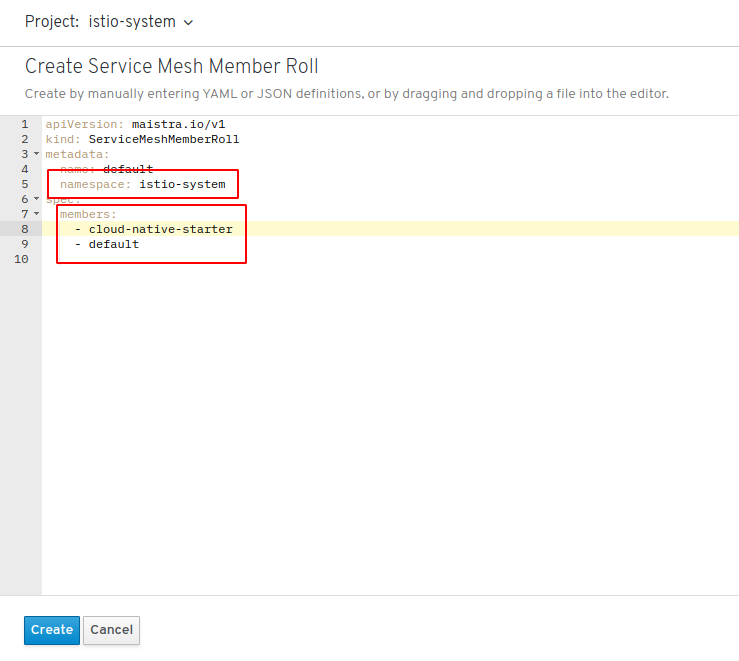
One last thing to do: you need to specify which projects are managed by your Service Mesh Control Plane and this is done by creating a Service Mesh Member Role.
In your project ‘istio-system’ go to “Installed Operator” and click on the “OpenShift Service Mesh” operator. In the Overview, create a new ‘Member Roll’:
In the YAML file make sure that namespace is indeed ‘istio-system’ and then add all projects to the ‘members’ section that you want to be managed.
Good to know: These projects do not need to exist at this time (in fact we are going to create ‘cloud-native-starter’ in a moment) and you can always change this list at any time!
Click “Create”. You are now ready to deploy an application.
Example Application
As an example I use one part of our OpenShift on IBM Cloud Workshop.
First step is to create a build config and a build which results in a container image being built and stored in the OpenShift internal image registry:
The instructions in the workshop to check for the image (part 1, step 3) no longer work, OpenShift 4 doesn’t use a Docker registry anymore and the new registry doesn’t have a UI. Check the build logs and wait until the image has been pushed successfully.
Before deploying the application, we need to change the deployment.yaml file in the deployment directory:
OpenShift Service Mesh uses an annotation in the Kubernetes Deployment definition to trigger the Istio Proxy or Sidecar injection into a pod. The tagging of a namespace that you may use on default Istio doesn’t work on OpenShift. With the “OpenShift way” you have control over which pods receive a sidecar and hence are part of the service mesh; build containers for example shouldn’t use a sidecar.
The annotation is ‘sidecar.istio.io/inject: “true” ‘ and the YAML file looks like this:
You also need to change the location of the image in the deployment.yaml. The registry service has changed between OpenShift 3.11 – on which the workshop is based – and OpenShift 4 in this article:
The second command creates the service for the deployment. Note: Without a service in place, the sidecar container will not start! If you check the istio-proxy log it will constantly show that it can’t find a listener for port 3000. That is the missing service definition, the error looks like this:
You can try if the example works by calling the API, e.g.:
curl -X GET "http://authors-cloud-native-starter.apps-crc.testing/api/v1/getauthor?name=Niklas%20Heidloff" -H "accept: application/json"
This will return a JSON object with author information.
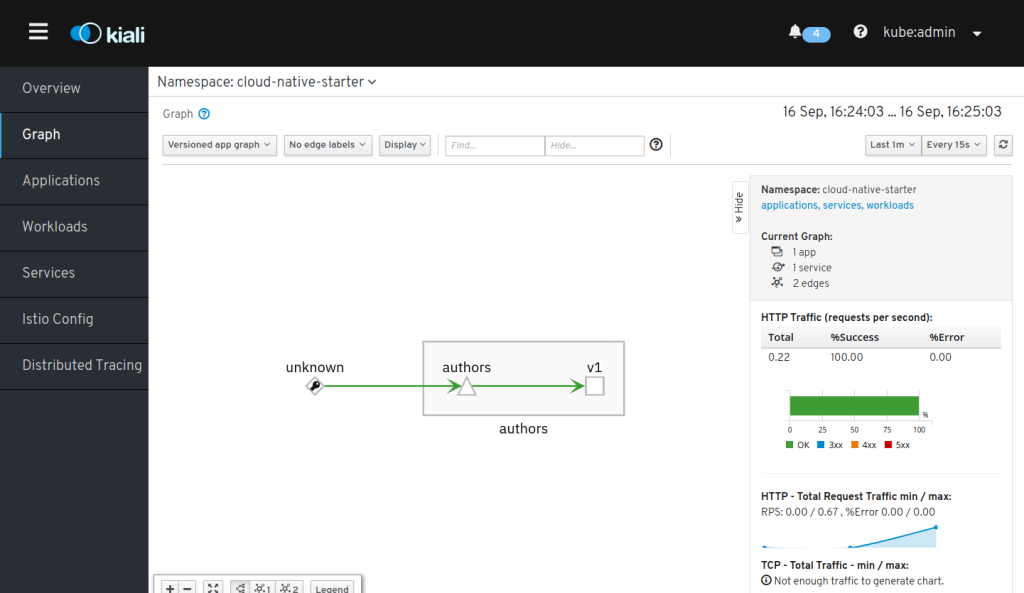
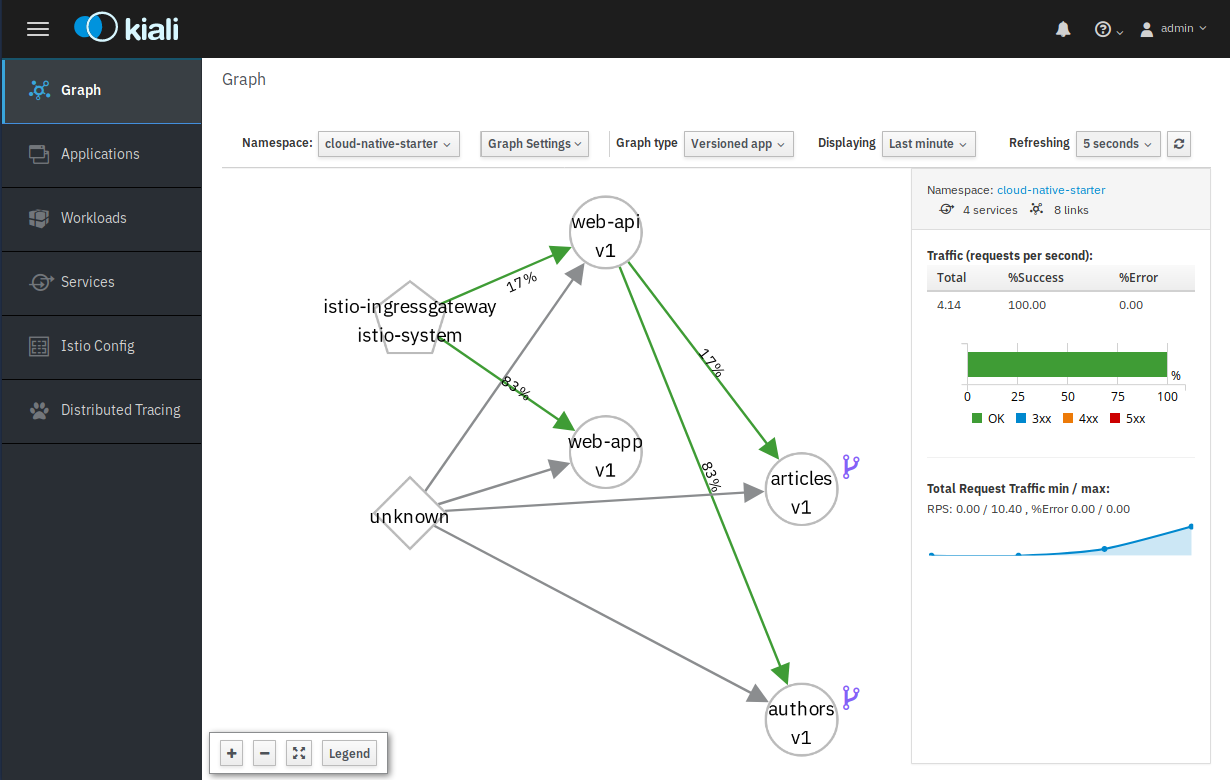
You can check if it works by “curl-ing” the address a couple of times and checking the result in Kiali (https://kiali-istio-system.apps-crc.testing):
[Nov 29, 2019: Another update to the Expiration section at the end]
I use Minishift on my laptop and have blogged about it. Minishift is based on OKD 3.11, the Open Source upstream version of OpenShift. An update of Minishift to OpenShift 4 never happened and wasn’t planned. I haven’t actually seen OKD 4.1 except for some source code.
But recently I found something called Red Hat CodeReady Containers and this allows to run OpenShift 4.1 in a single node configuration on your workstation. It operates almost exactly like Minishift and Minikube. Actually under the covers it works completely different but that’s another story.
CodeReady Containers (CRC) runs on Linux, MacOS, and Windows, and it only supports the native hypervisors: KVM for Linux, Hyperkit for MacOS, and HyperV for Windows.
This is the place where you need to start: Install on Laptop: Red Hat CodeReady Containers
To access this page you need to register for a Red Hat account which is free. It contains a link to the Getting Started guide, the download links for CodeReady Containers (for Windows, MacOS, and Linux) and a link to download the pull secrets which are required during installation.
The Getting Started quide lists the hardware requirements, they are similar to those for Minikube and Minishift:
4 vCPUs
8 GB RAM
35 GB disk space for the virtual disk
You will also find the required versions of Windows 10 and MacOS there.
I am running Fedora (F30 at the moment) on my notebook and I normally use VirtualBox as hypervisor. VirtualBox is not supported so I had to install KVM first, here are good instructions. The requirements for CRC also mention NetworkManager as required but most Linux distributions will use it, Fedora certainly does. There are additional instructions for Ubuntu/Debian/Mint users for libvirt in the Getting Started guide.
Start with downloading the CodeReady Containers archive for your OS and download the pull secrets to a location you remember. Extracting the CodeReady Containers archive results in an executable ‘crc’ which needs to be placed in your PATH. This is very similar to the ‘minikube’ and ‘minishift’ executables.
First step is to setup CodeReady Containers:
$ crc setup
This checks the prerequistes, installs some drivers, configures the network, and creates an initial configuration in a directory ‘.crc’ (on Linux).
You can check the configurable options of’crc’ with:
$ crc config view
Since I plan to test Istio on crc I have changed the memory limit to 16 GB and added the path to the pull secret file:
$ crc config set memory 16384
$ crc config set pull-secret-file path/to/pull-secret.txt
Start CodeReady Containers with:
$ crc start
This will take a while and in the end give you instructions on how to access the cluster.
INFO To access the cluster using 'oc', run 'eval $(crc oc-env) && oc login -u kubeadmin -p ********* https://api.crc.testing:6443'
INFO Access the OpenShift web-console here: https://console-openshift-console.apps-crc.testing
INFO Login to the console with user: kubeadmin, password: *********
CodeReady Containers instance is running
I found that you need to wait a few minutes after that because OpenShift isn’t totally started then. Check with:
$ crc status
Output should look like:
CRC VM: Running
OpenShift: Running (v4.x)
Disk Usage: 11.18GB of 32.2GB (Inside the CRC VM)
Cache Usage: 11.03GB
If your cluster is up, access it using the link in the completion message or use:
$ crc console
User is ‘kubeadmin’ and the password has been printed in the completion message above. You will need to accept the self-signed certificates and then be presented with an OpenShift 4 Web Console:
There are some more commands that you probably need:
‘crc stop’ stops the OpenShift cluster
‘crc delete’ completely deletes the cluster
‘eval $(crc oc-env)’ correctly sets the environment for the ‘oc’ CLI
I am really impressed with CodeReady Containers. They give you the full OpenShift 4 experience with the new Web Console and even include the OperatorHub catalog to get started with Operators.
Expiration
Starting with CodeReady Containers (crc) version 1.1.0 and officially with version 1.2.0 released end of November 2019, the certificates no longer expire. Or to be precise: they do expire, but crc will renew them at ‘crc start’ when they are expired. Instead, ‘crc start’ will print a message at startup when a newer version of crc, which typically includes a new version of OpenShift, is available. Details are here.
Kubernetes Operators are a Kubernetes extension that was introduced by CoreOS. On their website they explain it like this:
“An Operator is a method of packaging, deploying and managing a Kubernetes application. A Kubernetes application is an application that is both deployed on Kubernetes and managed using the Kubernetes APIs and kubectl tooling.”
IMHO, databases in Kubernetes are the perfect target for Operators: they require a lot of skill to install them — this typically involves things like stateful sets, persistent volume claims, and persistent volumes to name a few — and to manage them which includes updates, scaling up and down depending on the load, etc. An operator could and should handle all this.
CoreOS established OperatorHub.io as a central location to share Operators. I looked at the Database section there and found a Postgres-Operator provided by Zalando SE and decided to give it a try. This is my experience with it, maybe it is of use to others.
One of the easiest ways to test it is using Minikube. I wrote about Minikube before and I still like it a lot. You can try something new and if it doesn’t work, instead of trying to get rid of all the artefacts in Kubernetes, stop the cluster, delete it, and start a new one. On my notebook this takes between 5 and 10 minutes. So I started my Operator adventure with a fresh instance of Minikube:
I cloned the Github repository of Operator Lifecycle Manager (OLM) which
… enables users to do the following:
– Define applications as a single Kubernetes resource that encapsulates requirements and metadata
– Install applications automatically with dependency resolution or manually with nothing but kubectl
– Upgrade applications automatically with different approval policies …
There is an installation guide and I tried to follow the instructions “Run locally with minikube” but that failed, no idea why. I then simply did the “Manual Installation” and this works perfect on Minikube, too:
Once the OLM is running you can even get a nice UI, installation is described here. It looks a bit weird but what is does is download the Open Source OKD version of the OpenShift web console as Docker image, runs this image locally on your workstation, and connects it to your Kubernetes cluster which in my case is Minikube.
OKD Console with OperatorHub menu
In this list of Operators you can find the Zalando Postgres-Operator and directly install it into your cluster.
You click “Install” and then “Subscribe” to it using the defaults and after a moment you should see “InstallSucceeded” in the list of installed Operators:
The Operator is installed in the Kubernetes “operators” namespace. It allows to create PostgreSQL instances in your cluster. In the beginning there is no instance or Operand:
You can “Create New”: “Postgresql” … but the P dissapears later 🙂 and then you see the default YAML for a minimal cluster. The creation of a new PostgreSQL cluster only seems to work in the same namespace that the Operator is installed into so make sure that the YAML says “namespace: operators”.
Once you click “Create” it takes a couple of minutes until the cluster is up. The okd console unfortunately isn’t able to show the resources of the “acid-minimal-cluster”. But you can see them in the Kubernetes dashboard and with kubectl:
If you have “psql” (the PostgreSQL CLI) installed you can access the acid-minimal-cluster with:
In the okd / OLM dashboard you can directly edit the YAML of the PostgreSQL cluster, here I have changed the number of instances from 2 to 4 and “Saved” it:
Looking into the Kubernetes dashboard you can see the result, there are now 4 acid-minimal-cluster-* pods:
In my last blog I explained how to deploy our cloud native starter project on Minishift. Since early June 2019 there is a Red Hat OpenShift beta available on the IBM Cloud. It is currently based on OpenShift 3.11 and is a managed offering like the IBM Kubernetes Service on IBM Cloud. Our cloud native starter project is mostly based on Open Source technology and free offerings but while OpenShift is Open Source it is not free. During the beta there are no license fees but OpenShift does not run on the free cluster available with the IBM Kubernetes Service.
Logo: (c) Red Hat, Inc.
The deployment of the cloud native starter example is documented in our Github repo. Where are the main differences to the Minishift deployment?
There is no user installation of OpenShift: You create a Kubernetes cluster of type “OpenShift” in the IBM Cloud dashboard and the rest is taken care of. After typically 15 to 20 minutes you will gain access to the OpenShift web console through the IBM Cloud dashboard. A user and password has been automatically created via IBM Cloud Identity and Access Management (IAM).
To log in with the ‘oc’ CLI you can either copy the login command from the OpenShift web console, request an OAuth token from IBM Cloud dashboard, or use an IAM API key that you can create and store on your workstation. The latter is what we use in the OpenShift scripts in our Github project:
So while security aspects between Minishift and OpenShift on IBM Cloud are not different, there is no simple login with developer/developer anymore.
In Minishift we applied the anyuid addon to allow pods to run as any user including the root user. We need to do that in OpenShift, too, although this is not really considered best practice. But the Web-App service is based on an Nginx image and this is causing a lot of trouble in the security area. And I really didn’t want to spend a lot of time fixing this. The script ‘openshift-scripts/setup-project.sh‘ pulls the OpenShift Master URL for the ‘oc login’ in the other scripts, creates a project ‘cloud-native-starter’, and adds the anyuid security constraint to this project.
All deploy scripts use the binary build method of OpenShift: Create a build configuration with ‘oc new-build’ and then push the code including a Dockerfile with ‘oc start-build’., e.g.:
This triggers the creation of a build pod which will in turn create an image with the instructions in the Dockerfile and push the image into the OpenShift Docker Registry as an image stream. The binary build is able to perform the multistage build we use for some of the microservices. Deployment of the apps is then done with ‘oc apply’ or ‘kubectl apply’. Creating a route for a service exposes the service with a URL that is directly accessible on the Internet, no need to fiddle with NodePort etc.
Istio is currently not officially supported on OpenShift. There is a Red Hat OpenShift Service Mesh currently available as Technology Preview. The upstream project for this is Maistra and this is what I want to test next. But Maistra requires the so-called “admission-webhooks” for Sidecar auto-injection, and these are currently missing in the OpenShift on IBM Cloud master nodes. There is an issue open with IBM Development and they plan to include them in the near future. So for the time being we deploy the cloud native starter example on OpenShift on IBM Cloud without Istio. And I plan another blog once I am able to install Istio, stay tuned.
Initially I thought that different Kubernetes environments are more or less identical. I have learned in the past weeks that some of them are more and some are less so and there are always differences so here are my notes on deployments on Minishift. As a seasoned OpenShift user you might find it strange why I describe the obvious but if you come from a plain Kubernetes background like I did, this maybe helpful. Since I am still a noob in all things OpenShift maybe things are really done differently?
OpenShift enforces role based access control and security and thus enables strict separation of “projects” which are based on Kubernetes namespaces.
So in order to start a new project on OpenShift/Minishift, you create a project and apply some security policies to it. The project automatically includes a Kubernetes namespace of the same name and an “image stream” – also of the same name – to store Docker images in the OpenShift Docker registry. In my last blog, I wrote about Minishift setup and Istio installation and that Maistra, the Istio “flavour” I installed, is enforcing mTLS. Since we haven’t implemented mTLS in Cloud Native Starter, we need to apply a no-mtls policy to our projects name space. The setup-project.sh script does exactly this.
The final result in the Minishift Console
With Minikube, Docker images can be built in the Docker environment that runs in the VM (by using the “eval $(minikube docker-env)” command) and Kubernetes can pull the images directly from there.
With the IBM Cloud Container Registry (ICR), you can build images locally on your workstation, tag them for ICR, and then push them to the registry, or you can use the CLI to build them directly in the repository (“ibmcloud cr build“).
Minishift is similar to ICR: You can do the docker build, docker tag, docker push sequence, use the Minishift Docker environment for the build (“eval $(minishift docker-env)“), and then push the image to the OpenShift Docker Registry. This is what I do in the script “deploy-authors-nodejs.sh“:
Note the “docker login …“, this is required to access the OpenShift Docker Registry.
One issue here is the Docker version in Minishift, currently it is Version 1.13.1 (which is equivalent to Version 17.03 in the new Docker versioning scheme). We use multi-stage builds on Minikube for the articles and web-api service and for the web-app. This means, we use build containers as stage 1 and deploy the generated artifacts into stage 2 and thus into the final container image (example). But multi-stage build requires at least Docker Version 17.05. So for the web-app in script deploy-web-app.sh I use an OpenShift build option, “binary build”, which supports multi-stage build:
This creates a “build config” on OpenShift in our project, uploads the code to OpenShift into a build container, builds the image, and pushes it into the OpenShift Docker Registry, specifically into the image stream for our project.
And then I use “oc apply -f kubernetes-minishift.yaml” to create the Kubernetes deployment. Why not use the OpenShift “oc new-app” command? Because I want to specify the Istio sidecar inject annotation in the yaml file. I haven’t found a way to do that with “oc new-app”.
How can you access this service running on OpenShift? Again there are multiple options: OpenShift specific is to create a route (“oc expose svc/web-app“). Or Istio specific by using the Istio Ingress Gateway and a VirtualService using the Gateway.
Over the last weeks we have worked intensively on our Cloud Native Starter project and made a lot of progress. It is an example of a microservices architecture based on Java, Kubernetes, and Istio. We have developed and tested it on Minikube and IBM Cloud Kubernetes Service.
Currently we are enabling Cloud Native Starter to run on Red Hat OpenShift starting with Minishift.
OpenShift is Red Hat’s commercial Kubernetes distribution. There is a community version of OpenShift called OKD which stands for “Origin Community Distribution of Kubernetes”. OKD is the upstream Kubernetes distribution embedded in Red Hat OpenShift. And the there is Minishift. Like Minikube, it is an OKD based single node Kubernetes cluster running in a VM.
Minishift is currently running OKD/OpenShift Version 3.11 as latest version. OpenShift Version 4 will probably never be supported.
I have experimented with Minishift a while ago when I had a notebook with 2 CPU cores (4 threads) and 8 GB of RAM. That is not enough! My current notebooks has 4 CPU cores (8 threads) and 32 GB of RAM and it runs quite well on this machine.
If you like me come from a plain Kubernetes experience, OpenShift is a challenge. Red Hat enabled many security features like role based access control and also enabled TLS in many places. So you have to learn many things new. And while bringing up Minishift is quite simple (“minishift start”), installing Istio isn’t. There are instructions for OpenShift on the Istio website but they ignore Kiali and I don’t want to miss out on Kiali. And I was not able to get automatic injection to work because I couldn’t find the file to patch.
One day I stumbled over this blog by Kamesh Sampath from Red Hat. And then Istio install on Minishift is almost a breeze:
1. Set up a Minishift instance with some prerequisites
2. Download the Minishift Add-ons from Github
3. Install the Istio add-on
There are still some things missing and I have documented the process that works for me here.
A couple of comments:
The Istio add-on installs Istio with a Kubernetes operator which is cool. It is based on a project called Maistra which seems to be the base for the upcoming OpenShift Service Mesh. It installs a very downlevel Istio version (1.0.3), though. But the integration with OpenShift is very good and all security aspects are in place. For testing I think this works very well.
Did I mention security? Maistra by default seems to enable mTLS. Which results in upstream 503 errors between your services once you apply Istio rules. For the sake of simplicity we therefore decided to disable mTLS in our cloud-native-starter project for Minishift.
Automatic sidecar injection is also handled differently in Maistra/Istio: In our Minikube and IBM Kubernetes Service environments we label the namespace with a specific tag (“istio-injection=enabled”). With this label present, every pod in that namespace will automatically get a sidecar injected. Maistra instead relies on opt-in and requires an annotation in the deployment yaml file as described here. This requires enablement of “admission webhooks” in the master configuration file which is done by patching this file. Fortunately, this is made very easy in Minishift. All you need to do is enable an add-on (“minishift addon enable admissions-webhook”).
Logging and Monitoring have always been important but in a distributed microservices architecture on a Kubernetes cluster it is even more important: watching the ever changing components of a cluster is like “guarding a bag of fleas” as the German proverb says. Even our demo “Cloud Native Starter” has at least 4 or 5 pods running that all create logs that at some point when something doesn’t work you need to look at. There are plenty of articles around logging in a Kubernetes cluster with many different solutions. What is important to me as a developer is that I don’t want to care about maintaining it. I need a logging and monitoring solution but I want somebody else to keep it running for me. Fortunately, IBM Cloud is offering that in the form of “IBM Log Analysis with LogDNA” and “IBM Cloud Monitoring with Sysdig”.
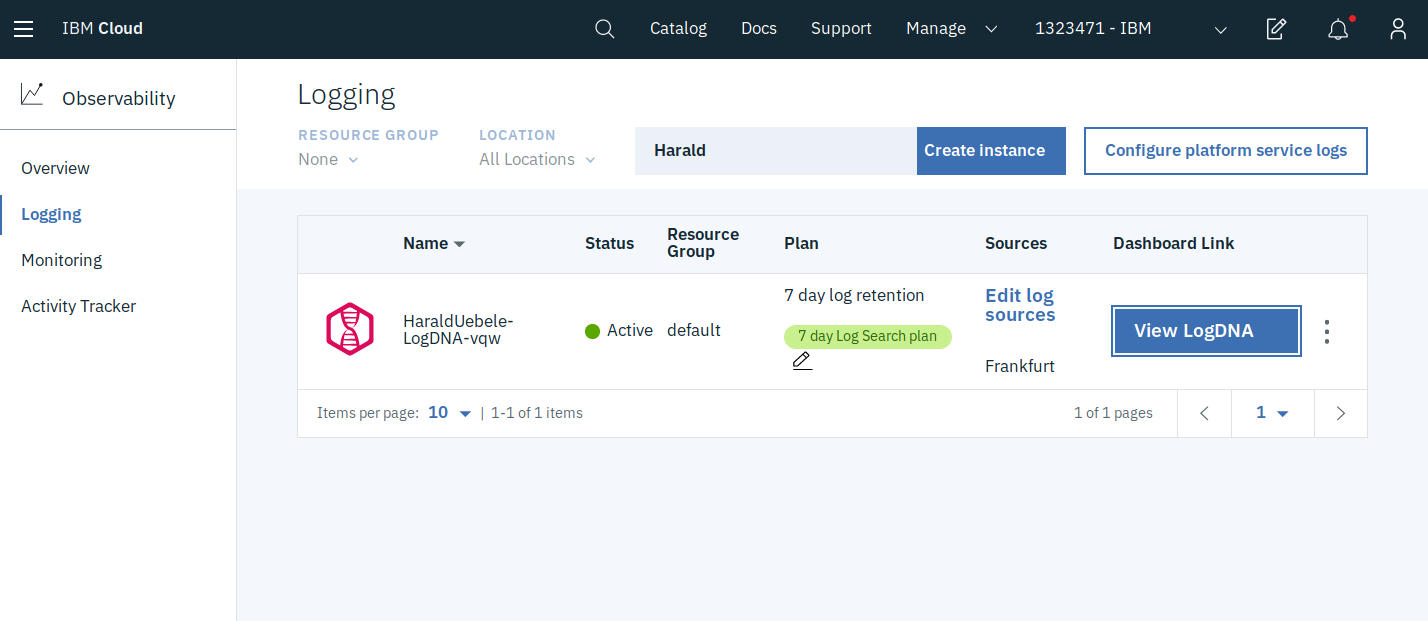
Logging and Monitoring are somewhat hidden in the IBM Cloud dashboard. You find them in the “Observabilty” area of the “Burger” menu where you can create the services, learn how to configure the sources, and access their dashboards.
LogDNA can be used with a Kubernetes Cluster running on the IBM Cloud and it can also be used with a Minikube cluster. It is available in the IBM Cloud Datacenters in Dallas and Frankfurt. There is free (lite) version available but this is limited in its features.
Once a LogDNA instance has been created, the next thing to do is to “Edit log sources”. There are several options, we are only interested in Kubernetes here:
Two kubectl commands need to be executed against the Kubernetes cluster (IBM Kubernetes Service or Minikube work).
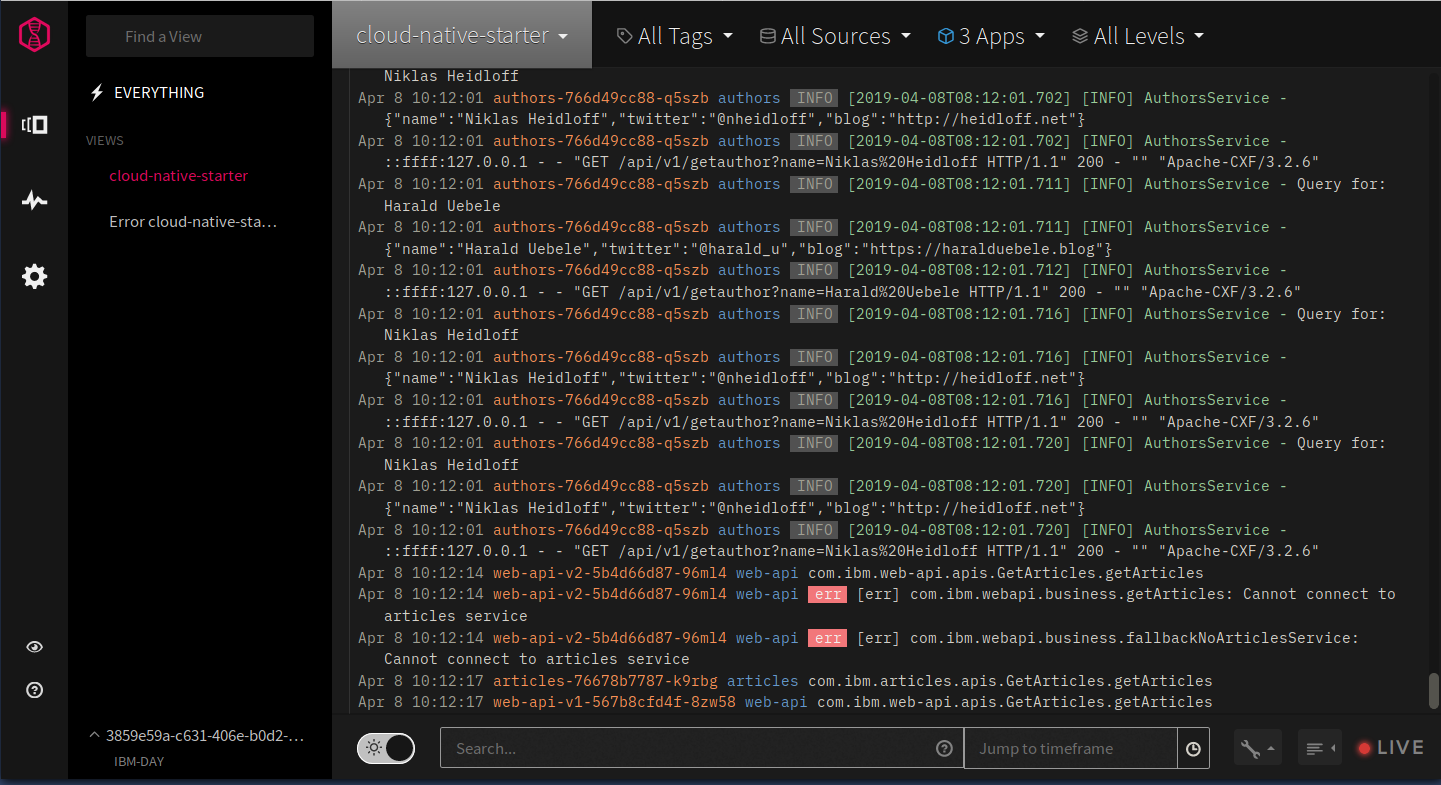
The first command creates a Kubernetes secret holding my specific LogDNA ingestion key which is required to write log events into my LogDNA instance. The second command creates a logdna-agent daemon set in the Kubernetes cluster which creates a pod on every Kubernetes worker node. No further installation or configuration is required. If you click on the “View LogDNA” button you’ll see the dashboard:
Notice the filters in the header area. In this screenshot I have filtered on 3 Apps, the listing shows “authors”, “web-api”, and “articles”. I can further filter on showing errors only, save that as a view, and attach an alerting channel to it, for example email or a Slack channel. You can find more infos here.
Sysdig can be used with a Kubernetes Cluster running on the IBM Cloud and it can also be used with a Minikube cluster, too. It is available in the IBM Cloud Datacenters in Dallas, London, and Frankfurt. There is trial version available with limited features which expires after 30 days.
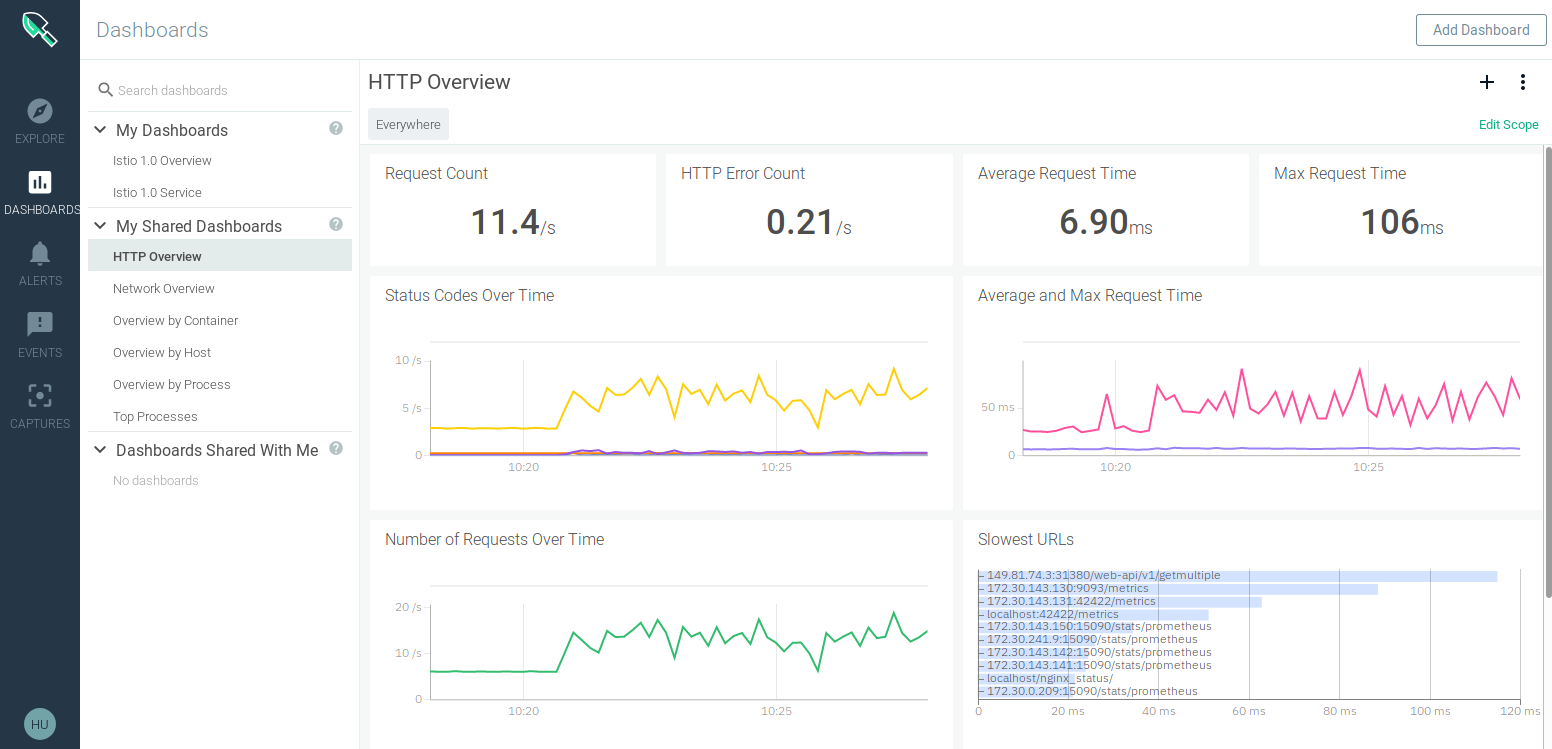
Again, once the Sysdig instance has been created, go to “Edit sources”. There are instructions for Kubernetes, Linux, and Docker. The Kubernetes instructions first explain how to logon to the IBM Cloud and then access the Kubernetes cluster with ibmcloud CLI, this is of course not required for Minikube. Lastly there is a curl command that downloads and install the sysdig agent for Kubernetes. Again, there is no further configuration required. The “View Sysdig” button opens the Sysdig dashboard:
There are several predefined dashboards including 2 predefined Istio dashboards which are not available in the trial version of Sysdig.
In my last blog I have described a project we are working on: Cloud Native Starter. It is a microservices architecture, written mostly in Java with Eclipse MicroProfile, and using many Istio features. We started to deploy on Minikube because that is easy to implement if you have a reasonably powerful notebook. Now that everything works on Minikube, I wanted to deploy it on the IBM Cloud, too, using IBM Cloud Kubernetes Service (IKS).
IKS is a managed Kubernetes offering that provides Kubernetes clusters on either bare metal or virtual servers in many of IBMs Cloud datacenters in Europe, the Americas, and Asia Pacific. One of the latest features (currently beta) are cluster add-ons to automatically install a managed Istio (together with Kiali, Jaeger, Prometheus, etc) onto an IKS cluster. You can even install the Istio Bookinfo sample with a single click, Knative is also available as preview.
There is even a free (lite) Kubernetes cluster available (single node, 2 vCPUs, 4 GB RAM) but you need an IBM Cloud Account with a credit card entered in order to use it, even if it is free of charge. I have heard stories that there was too much Bitcoin mining going on on the lite clusters, go figure! You can also try and get an IBM Cloud promo code, we hand them out at conferences where we are present, your next chances in Germany are JAX in Mainz, WeAreDevelopers and DevOpsCon in Berlin, ContainerDays in Hamburg .
There is also an IBM Cloud Container Registry (ICR) available, this is a container image repository comparable to Dockerhub but private on the IBM Cloud. You can store your own container images there and reference them in Kubernetes deployment files for deployment on the IBM Cloud. You can even use ICR to build your container images.
I have created scripts to deploy Cloud Native Starter onto the IBM Cloud and documented the steps here. Here I want to point out the few things that are different and very specific when deploying to IBM Cloud Kubernetes Service compared to deploying to Minikube
First, you need to be logged on the IBM Cloud of course which you do with the ibmcloud CLI, then you need to set the cloud-based Kubernetes environment configuration, and finally login to the Container Registry, too $ ibmcloud login
$ ibmcloud region-set us-south
$ ibmcloud ks cluster-config <clustername>
$ ibmcloud cr login
After that, ‘kubectl’ and ‘docker’ commands work with the IBM Cloud and not a local resource. ‘ibmcloud ks cluster-config’ is comparable to the ‘minikube docker-env’ for Minikube.
‘ibmcloud ks cluster-config’ outputs an ‘export KUBECONFIG=/…/… .yaml’. Copy and paste this export statement into your shell and execute it. This statement needs to be executed every time a new shell is opened where a kubectl command should run on your IKS cluster!
This is the command to build the container image for the Authors Service API locally or on Minikube: $ docker build -f Dockerfile -t authors:1 .
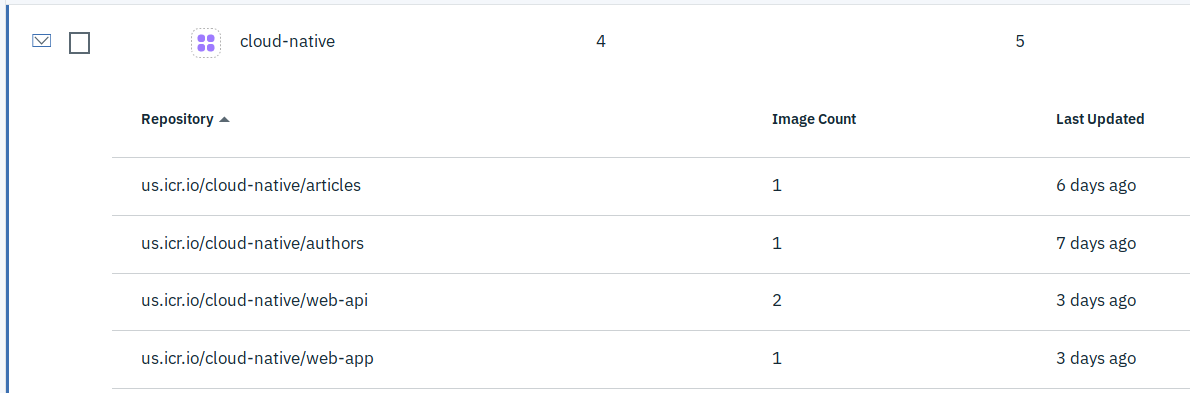
To build the image on the IBM Container Registry requires this command: $ ibmcloud cr build -f Dockerfile –tag us.icr.io/cloud-native/authors:1 .
‘cr’ is the subcommand for Container Registry, ‘us.icr.io’ is the URL for the Registry hosted in the US, and ‘cloud-native’ is a namespace within this registry. This is the dashboard view of the Registry with all images of Cloud Native Starter:
The deployment YAML files need to be adapted to reference the correct location of the image. This is the spec for Minikube with the image being locally available in Minikube:
Everything else is identical to Minikube in the files. In my deployment scripts, I use ‘sed’ to automatically create new deployment files.
Deploying to IKS is not different to deploying to Minikube, just make sure that the KUBECONFIG environment is setup to use the IKS cluster.
A lite (free) Kubernetes cluster on the IBM Cloud has no Ingress or Loadbalancer available. That is reserved for paid clusters. Istio, however, has its own Ingress (istio-ingressgateway) and this is accessible via a NodePort, http on port 31380, https on port 31390. To determine the public IP address of an IKS worker node, issue the command: $ ibmcloud ks workers <clustername>
The result looks like this:
To access the Cloud Native Starter webapp, simply point your browser to http://149.81.xx.x3:31380
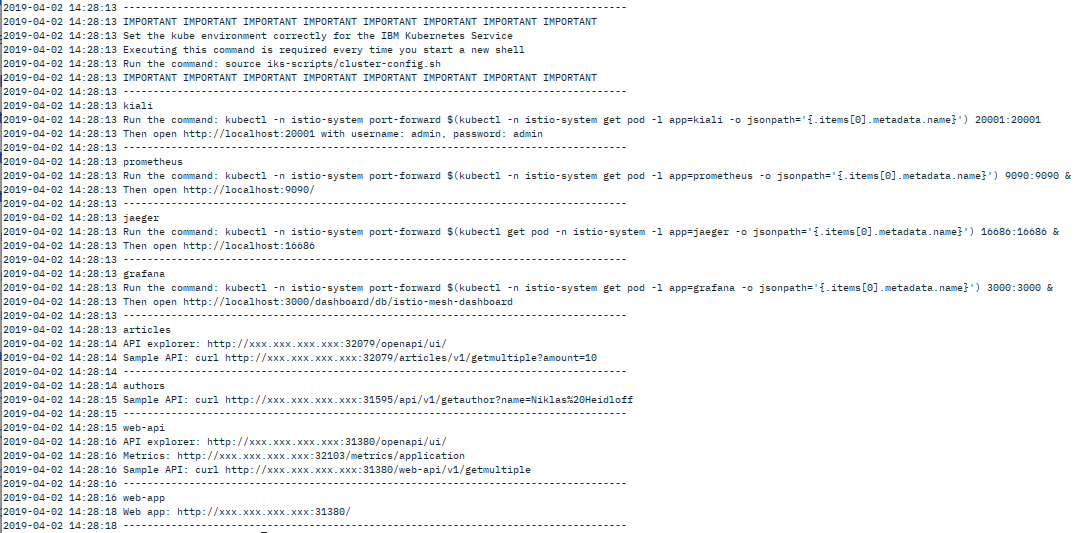
In our Github repository is a script iks-scripts/show-urls.sh that will point out all important URLs on the IBM Cloud deployment, including the commands to access Kiali, Jaeger, etc.














 Last week I wrote about
Last week I wrote about