My colleague Niklas Heidloff has started to create another version of our Cloud Native Starter using a reactive programming model, and he has also written an extensive series of blogs about it starting here. He uses Minikube to deploy the reactive example and I have created documentation and scripts to deploy it on CloudReady Containers (CRC) which is running Red Hat OpenShift 4.
The reactive version of Cloud Native Starter is based on Quarkus (“Supersonic Subatomic Java”), uses Apache Kafka for messaging, and PostgreSQL for data storage of the articles service. Postgres is accessed via the reactive SQL client. Niklas has blogged about all of the details.
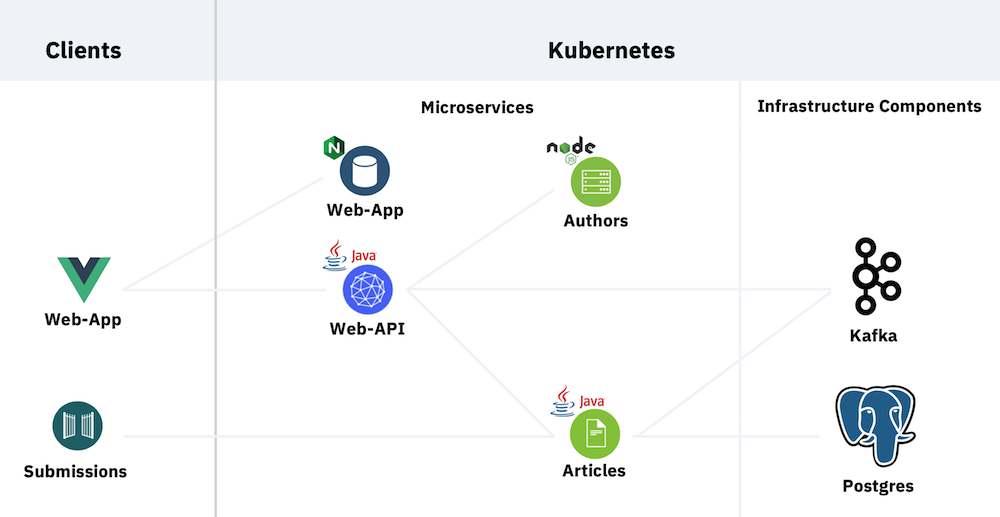
The deployment on OpenShift is very similar to the deployment of the original Cloud Native Starter which I have written about in my last blog.
The services (web-app, web-api, authors, articles) are build locally in Docker, then tagged with an image path suitable for the OpenShift image repository, then pushed with Docker into the internal repository.
Two things are different, though:
- The reactive example currently doesn’t require Istio, no need to install it, then.
- Kafka and Postgres weren’t used before.
I install Kafka using the Strimzi operator, and Postgres with the Dev4Devs operator.
In the OpenShift OperatorHub catalog, the Strimzi operator is version 0.14.0, we need version 0.15.0. That’s why I use a script to install the Strimzi Kafka operator and then deploy a Kafka cluster into a kafka namespace/project.
The Dev4Devs Postgres operator is installed through the OperatorHub catalog in the OpenShift web console into its own namespace (postgres).
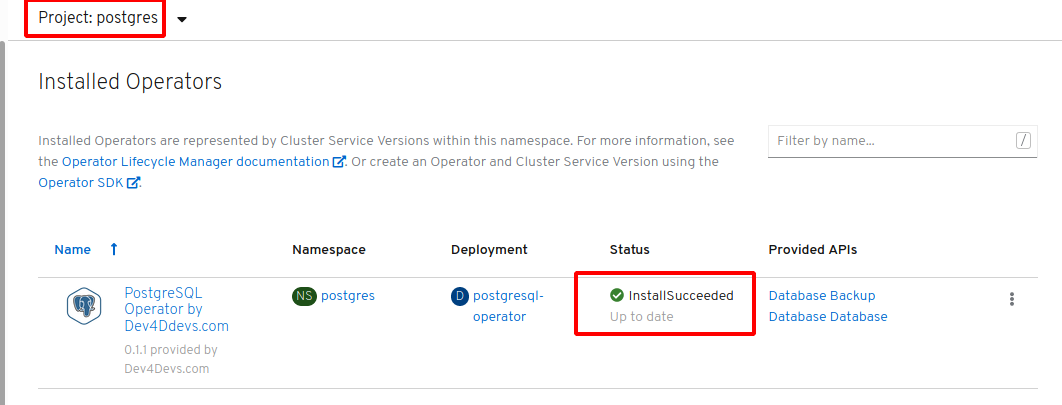
An example Postgres “cluster” with a single pod is deployed via the operator into the same namespace/project.
Using operators makes it so easy to install components into your architecture. The way they are created in this example is not really applicable to production environments but to create test environments for developers its perfect.